바둑은 고전 게임 중 탐색 범위가 가장 넓고 보드의 상황을 평가하는 것이 어려워서 인공지능의 가장 큰 숙제 중 하나였다. 체스와 퀴즈게임에서 세계챔피언을 이기는 현재도 당분간 바둑만큼은 사람이 인공지능보다 나을 것으로 예상되어 왔다.
데미스 하사비스 구글 딥마인드 CEO는 1국이 끝난 후에 "두 신경망을 통한 직관 모방이 알파고 핵심이라고 강조했다. 머신러닝을 통해 스스로 원리를 학습하도록 했다"며 "복잡도가 높은 바둑에서 기존 프로그램 대비 성능을 대폭 개선"했다고 밝혔다.
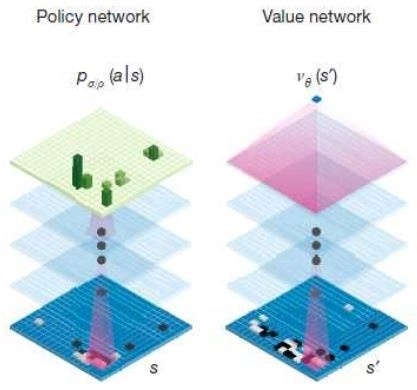
데미스 하사비스가 말한 두 신경망은 정책망과 가치망을 말한다. 정책망은 모든 경우의 수를 계산하지 않게 수를 줄여주고 가치망은 이 가운데 승률이 가장 높은 수를 판별해낸다.
궁금하면 알려주는 본지에서 알파고의 두 신경망 작동원리를 기술적으로 파헤쳐본다.
1. 경우의 수(Search Space) 줄이기
인공지능으로 게임을 구현하면 주로 게임 트리를 구성하고 최적의 경로를 예측하는 게임 트리 탐색 알고리즘을 사용한다.
체스나 장기, tic-tac-toe 와 같이 두 플레이어가 번갈아가며 수를 두는 게임에 주로 사용되는 알고리즘이다.
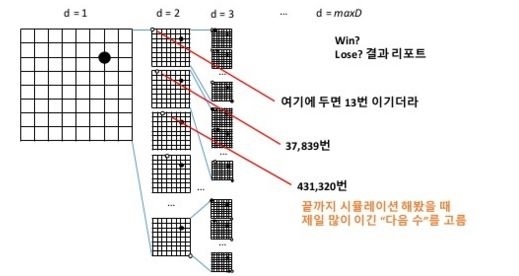
알파고는 게임 트리를 이용하여 다음 수를 미리 예측하고 가장 유리한 수를 찾는다. 아래 그림을 보면 첫번째 착점을 d=1이라고 한다면 다음 착점은 무수히 많은 착점의 확률이 있다.
이렇게 많은 착점을 계산한다는 것은 불가능하다. 우주의 원자보다 더 많은 경우의 수를 가지고 있기 때문이다. 바둑은 10의 170승의 가지수를 가진다. 그러면 알파고는 어떤 알고리즘을 가졌을까?
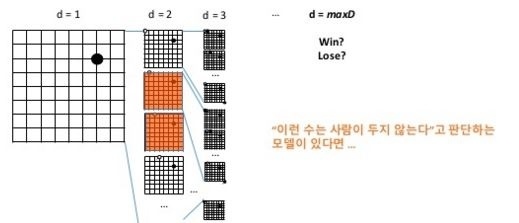
(1) 사람이 잘 두지 않는 후보군 줄이기 ("action" 후보군 줄이기(Breadth Reduction))-지도학습(supervised learning)이란
게임에서 시작부터 끝까지 모든 상태에 대한 완전한 탐색은 단순한 게임을 제외하고 현실적으로 불가능에 가깝다.
알파고는 사람이 잘 두지 않는 착점을 제외한다. 경우의 수를 줄이기 위함이다.

바둑(19x19)보다 탐색 정도가 낮은 체스(8x8)의 경우만 해도 완전한 게임트리에는 약 1040개의 노드가 존재한다. 체스는 약 35의 80을 제곱한 경우의 수가 존재한다는 말이다. 바둑은 게임중에서도 극단적으로 계산량이 많아서 가장 어려운 문제로 알려져 있다. 바둑은 약 250의 150을 제곱한 경우의 가지의 수다.
알파고가 학습을 했다는 것은 이 경우의 수를 줄이는 연습을 했다는 것이다. KGS Go Server의 실제 대국 기보로부터 3000만 가지 바둑판 상태를 추출하여 이 중 약 2900만 개를 학습에 이용하고, 나머지 100만 가지 바둑판 상태를 시험에 이용했다.사람이 다음 수를 두는 경향을 모델링 한 것이다. 이것을 지도학습(supervised learning)이라 부른다.
(2) 프로 바둑기사 따라하기 (supervised learning) -강화학습(reinforcement learning)이란
다음은 강화학습(reinforcement learning) 개념이다. 지도학습의 결과로 구해진 정책네트워크는 사람의 착수 선호도를 표현하지만 이 정책이 반드시 승리로 가는 최적의 선택이라고 볼 수 없다.
이것을 보완하기 위해 지도학습 으로 구현된 정책 네트워크와 자체대결을 통해 결과적으로 승리하는 선택을 “강화”학습함. 강화학습의 핵심은 정책 네트워크 간에 경기를 진행하고(self-play), 이로부터 도출된 경기결과(승패)를 바탕으로 이기는 방향으로 가도록 네트워크의 가중치를 강화(개선)하고. 강화 후에 기존 바둑프로그램인 Pachi와 대결하여 85%의 승률을 보인다고 알려졌다.

처음에는 지도학습의 결과를 그대로 이용하여 경기를 진행하지만 학습이 진행되면서 여러 버전의 네트워크가 생성되며 이들 간의 강화학습을 통해 실제로 승리하는 빈도가 높은 쪽으로 가중치가 학습된다.
AlphaGo의 몬테카를로 트리 탐색은 다음 수를 찾기 위해 현 상태에서 나와 상대가 모두 동일한 정책망을 가진 것으로 가정하고 여러 번 시뮬레이션을 돌려서 가장 높은 빈도로 선택한 수를 택하는 방식이다.
이 방법은 모든 트리를 탐색하지 않아도 좋은 성능의 장비에 의해 충분한 시뮬레이션을 돌릴 수 있으면 최적에 가까운 결과를 내는 것으로 알려져 있다. 구글은 충분한 시뮬레이션을 위해 병렬처리를 지원하고 많은 CPU와 GPU를 할당하여 계산한다
알파고가 이세돌 9단과 대국을 하면 할 수록 이세돌 9단이 선호하는 착점이나 잘 두지 않는 착점을 학습한다. 이것을 보고 알파고가 스스로 학습한다고 이른다.
알파고의 학습범위나 게임 성능은 상당한 수준일 것이며 판후이 선수와 기존 기보의 학습이나 심지어 이세돌 9단의 과거 기보도 학습이 되어 있다는 평이다.
2. 알파고와 기존 바둑 게임프로그램 토너먼트 결과는
알파고는 기존 바둑 프로그램과의 대결해 494승 1패를 기록했고, 유럽 챔피언 판 후이에게도 5:0 승리라는 경력을 갖고 있는데요. 알파고는 기존 바둑 프로그램과의 대결해 494승 1패를 기록했고, 유럽 챔피언 판 후이에게도 5:0 승리라는 경력을 갖고 있는데요. 사람으로 치면 1000년이 걸린다는 100만 번의 대국 연습을 4주 만에 소화, 상대방의 수를 예측하는 확률 57%까지 상승시켰다고 합니다.
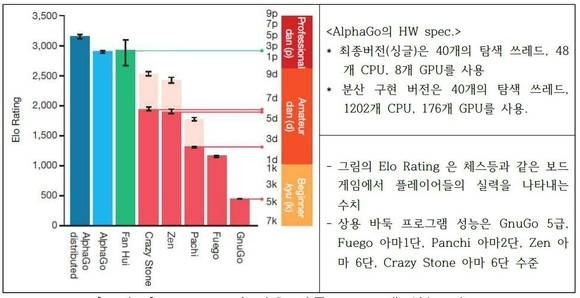
알파고는 돌을 놓는데 걸리는 계산시간은 최대 5초다. 알파고(AlphaGo)는 기존의 바둑 게임 프로그램들과의 토너먼트에서 총 495게임 중 494번 승리하여 승률 99.8%다. 4점 접바둑 게임의 경우에는 CrazyStone, Zen, Pachi 와의 대국에서 각각 77%, 86%, 99%의 승률을 보였다. (분산 AlphaGo vs. AlphaGo) 분산 AlphaGo의 승률이 77%다. 토너먼트 결과 AlphaGo 는 Elo Rating 2890 의 높은 점수를 얻었다.

알파고는 먼저 '정책망'을 통해 바둑돌을 둘 수 있는 위치를 살펴본 후 확률이 높은 위치로 탐색의 범위를 좁힌다. 그 후 좁아진 탐색 범위 내에서 다시 '가치망'을 가동시켜 각각 위치의 승률을 계산한다. 인간이 모든 경우의 수를 검토하지 않고 돌을 '둘 만한' 곳을 찾아 수를 읽는 것과 유사한 처리 방식을 갖추고 있다. 알파고를 개발한 구글 딥마인드에 따르면 알파고는 단순한 계산을 넘어서 인간의 '직관'을 흉내낼 수 있도록 설계됐다.
[2편에 계속] [알파고의 작동 원리]② 판세(Depth Reduction) 평가하기
참고문헌 : 네이처지에 실린 논문 "Mastering the game of Go with deep neural networks and tree search"과 ( http://www.nature.com/nature/journal/v529/n7587/full/nature16961.html ) Shane Moon님의 슬라이드 ( http://www.slideshare.net/ShaneSeungwhanMoon/ss-59226902 )